Newsletter · Issue #1 · Article 1
Generative AI research in year 2025: Bits and a big piece?
Our first issue explores the highlights of GenAI research from 2025. To celebrate the launch of the newsletter, we are releasing this collection as a series of articles over the coming weeks.

How to read the GAI Team newsletter
The Prologue - From the Hammock
I went out and draped my hammock between the nearest trees to read through the most important recent papers released in the AI field. Obviously, while I could hammock in minus 15 Celsius, reading dense research in the freezing cold felt like unnecessary heroism, so the hammock was strictly a mental image (yes, I miss summer). But I still had a cup of hot coffee, so here we are.
This Issue of the newsletter attempts to present some of the best work in AI research from around 2025. To celebrate our launch, Issue 1 is a special collection that we will publish sequentially, releasing one article at a time on our website. As AI is the most funded endeavor in human history, it is impossible to catch every development, and I want to remind you that this collection is just a tiny fraction of the whole. However, these selected papers highlight areas and concepts the field is currently wrestling with, which should help you gain a better understanding of the broader trajectory.
I will be offering my personal commentary in the “Tomi’s Take” sections, but please beware, I might actually be right about a few things a year from now! Please refer to How to read the GAI Team newsletter for an easier, more customized ride!
Context
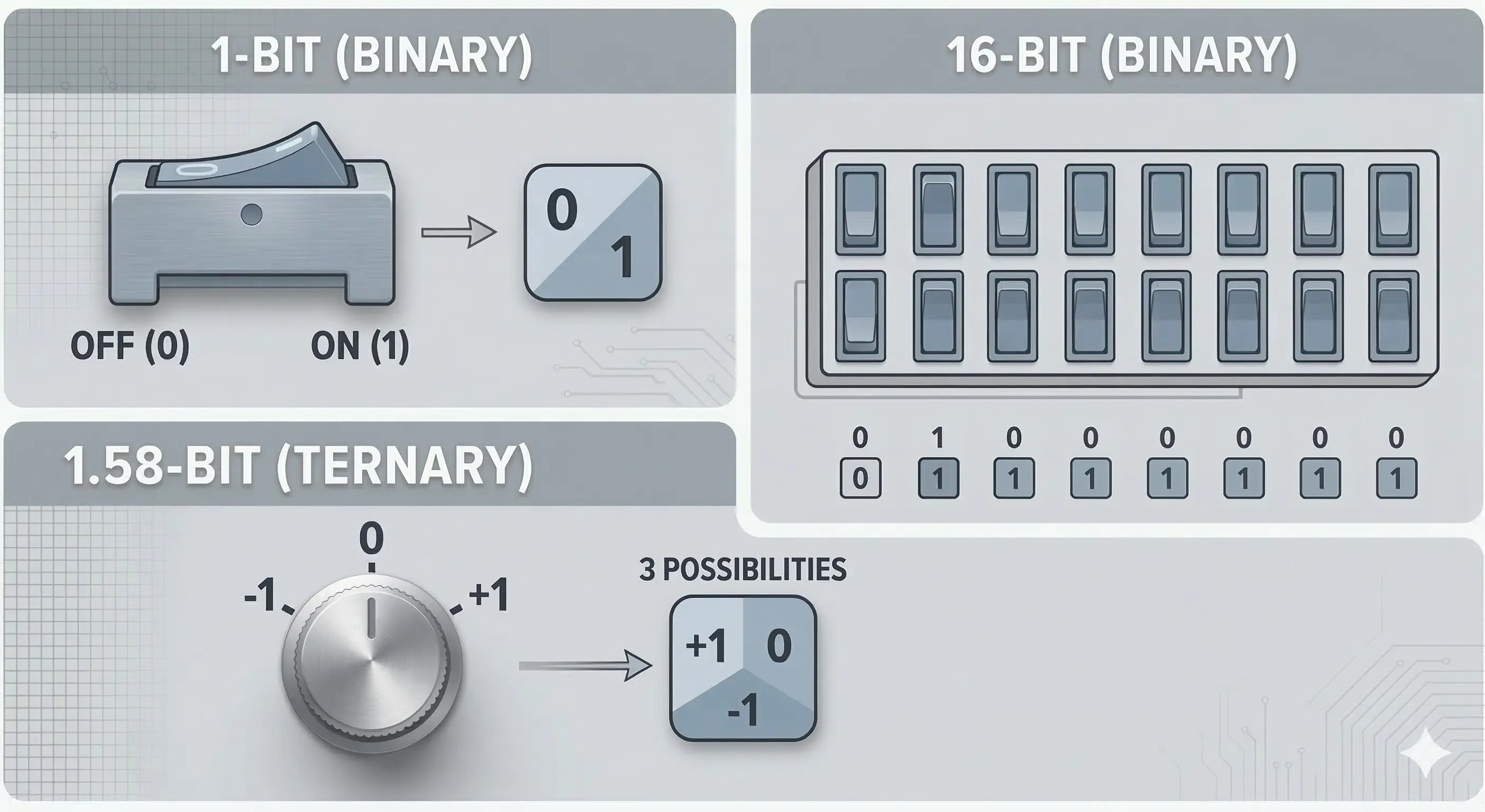
The BitNet b1.58 2B4T Technical Report introduces a fundamentally new way to build AI models to save computing power. Instead of storing the neural network’s weights as high-precision 16-bit numbers, this architecture restricts them to just three states. This drastically cuts the memory and energy footprint when the model is used. While the change theoretically limits the model’s expressive power, the benchmarks indicate practically no drop in performance.
Baseline
The researchers trained a 2-billion parameter model that matches the performance of standard, full-precision open models in its size class across language, math, and coding benchmarks. However, it does so using a fraction of the resources, such as memory and electricity. This matters because it fundamentally alters the physical and financial limits of deploying AI.
While 2-billion parameter models are very small in the world of Large Language Models (LLMs), they still require a lot from the hardware. You can’t exactly run one on your Nokia phone from 1999. But you can run this on something like a Raspberry Pi or a modern smartphone.
One critical note here is the difference between deploying and training. The training process for this model was still heavily resource-intensive because the system required high-precision 16-bit “master weights” in the background to learn properly. However, unlike older methods that train normally and just “dilute” the weights afterward, which degrades performance, this model was natively trained to operate in its ternary state from day one.
By making the weights so computationally “light,” the researchers showcase that models trained using their system can squeeze into a smaller amount of memory and thus capable models on local devices is one step closer to happening in reality. The scaling of this method is yet to be proved, but the researchers also note it as one future research direction.
Tomi’s Take
The biggest achievement of this paper isn’t the ternary system itself, rather it is the proof that we likely don’t need high-precision weights at all to achieve high-performing models. The numbers point to a massive drop in estimated energy consumption. To put those savings into real-world perspective: if running standard AI models required the entire electricity grid of Finland, this 1-bit model could run entirely on approximately the output of the Olkiluoto 1 reactor.
Aside from the raw energy savings, the memory reduction is a massive win for edge computing. It proves we can squeeze highly capable models directly onto local devices without needing a supercomputer in your backpack (no, that’s not a thing).
However, I don’t think this alone is enough of a paradigm shift to make OpenAI and the big players switch to ternary training overnight. Why? Because our current hardware ecosystem is not perfectly compatible with it. The physical silicon we use right now isn’t built for 1.58-bit math, and the initial training still requires as much raw computing power and high-precision effort as traditional models.
So, without new hardware, we are stuck with that mental image of hammocking from the intro; it’s a clever workaround, but it’s definitely not a real summer day at the beach.
All of this doesn’t mean you can’t run it. The researchers built custom software to make it work on today’s hardware, but until the physical silicon catches up to support these “off-bit” operations natively, we cannot unlock its maximum theoretical efficiency. Still, there can absolutely be solutions that leverage this right now, especially for local models under the 70B parameter mark.
I can’t wait to see someone developing around a 20B model using this system. My personal assessment is that even fine-tuned LLMs under 10B are very hard to use in the real world for anything other than basic, singular tasks, but after hitting around 14B parameters, the models start to become “promptable” and allow for complex or creative cases. Going beyond 14-24B is rarely worth the extra computing and memory requirements. So, if 1.58-bit system scales to these ranges, it’s a major win for local environments.
Theory
To understand the core rationale, we have to look at the math behind the “1.58-bit” name. Normally models store their neural network weights as 16-bit. BitNet throws that out and restricts the weights to just three discrete states. Mathematically, it takes roughly 1.58-bits of data to encode three distinct states, hence the name.
This odd number is exactly why it is not directly compatible with current hardware. Silicon is fundamentally built to read strict binary, clean powers of two like 8-bit or 16-bit like “1010 1010 1010 1010”. Trying to run a base-3 ternary “-1, 0, +1” system on hardware designed for base-2 binary “0, 1” creates a structural mismatch.
Quick sidenote: Obviously, the developers could have just used standard 2-bit quantization instead of ternary, giving them four clean binary options “00, 01, 10, 11” that hardware understands natively. Why didn’t they? While the paper doesn’t state this explicitly, here is my read: a standard non-zero 2-bit setup is missing a true “neutral.” In a neural network, that 0 is critical. It allows the model to completely ignore irrelevant data. Without the ability to state that “this doesn’t matter”, the model is forced to add or subtract every single input it receives. Without that neutral gear, the model risks becoming an opinionated mess that can only scream “yes” or “no” at every piece of data it sees.
To actually build this, the model was trained in 3 stages: aggressive pre-training, supervised fine-tuning, and Direct Preference Optimization (DPO). The dataset used for training contained 4 trillion tokens and consisted of text and code derived from the web, as well as synthetically generated mathematics. During training, the researchers quantized the weights during the forward pass but kept high-precision master weights running in the background. This workaround allowed the model to adjust its weights precisely during backpropagation, while natively training for ternary execution from day one.
There are notable engineering feats achieved alongside the research paper release:
- First is that they wrote custom CUDA kernels to force current GPUs to handle 1.58-bit math by packing the ternary weights into standard 8-bit formats.
- The second is that they released the bitnet.cpp for CPU inference, allowing the model to run efficiently on standard processors without relying on bloated, generic quantization libraries.
That’s the very first of the research papers we are going to go over, and there’s more to come! Hope to see you here next time! Comments and feedback can be delivered on LinkedIn.
References
Ma, S., Wang, H., Huang, S., Zhang, X., Hu, Y., Song, T., Xia, Y., & Wei, F. (2025). BitNet b1.58 2B4T technical report. arXiv. https://doi.org/10.48550/arXiv.2504.12285
How did you find this?
Anonymous count, no tracking.